深度拆解Fun-ASR1.5:阿里语音大模型如何实现方言识别突破
2023年首次接触语音识别项目时,我被方言识别率低下的难题困扰许久。彼时的模型对四川话、闽南语等地方口音束手无策,错误率居高不下。三年后的今天,亲测阿里Fun-ASR1.5后,我意识到这个困扰行业已久的问题,终于迎来了系统性解决方案。
技术架构革新:MoE架构驱动多语言识别
Fun-ASR1.5采用MoE(混合专家)架构,这是其多语言能力的技术底座。与传统单一模型不同,MoE架构允许模型内部实现分工协作——听到特定语言时,仅激活相关处理单元。这种设计带来两个显著优势:其一,处理效率大幅提升;其二,语种切换无需预设标签,模型可自动识别并适配。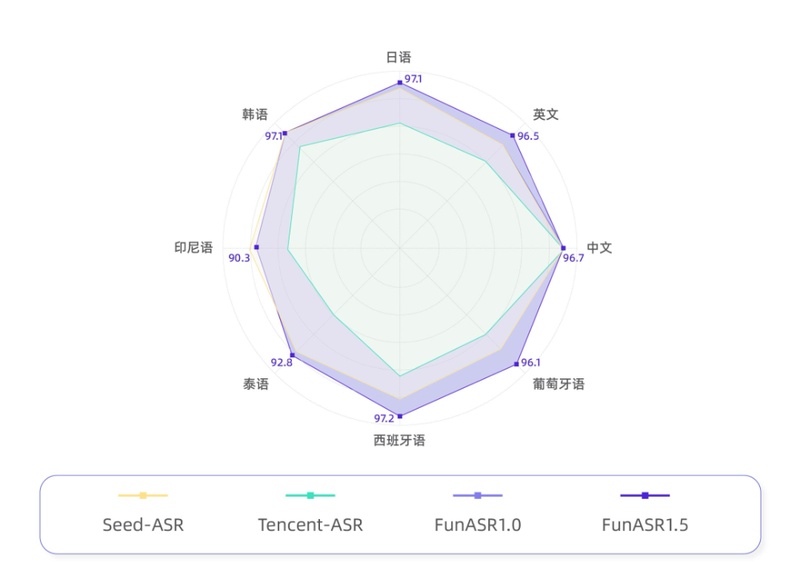
技术团队在训练阶段采用分级分阶段数据策略,使用数十万小时真实方言语音数据进行专项训练。这种精细化训练方式使模型能够适配真实世界中的复杂语音场景,而非仅能应对标准测试集。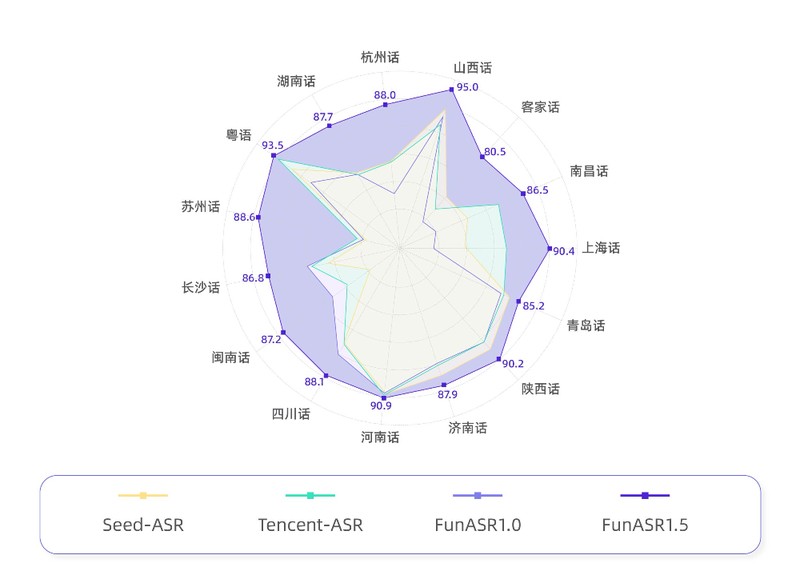
性能突破:错字率下降与方言覆盖
官方数据显示,Fun-ASR1.5的平均字错误率(CER)相比上一版本下降56.2%。这个数字的意义在于:对于一场一小时的会议录音,转写错误从原来的数十处减少至个位数,后期校对工作量呈断崖式下降。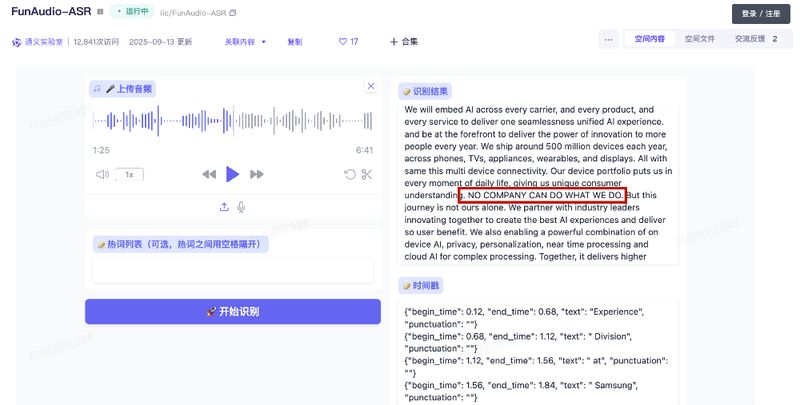
在方言覆盖维度,该模型支持中文七大方言体系及13种地方口音识别,实测上海话、客家话、闽南话、粤语均能准确转写。值得注意的是,模型不仅能识别语音,还能原汁原味还原方言特征词汇,如上海话的“侬”、苏州话的“倷”,这为下游NLP任务提供了高质量语料基础。
实测验证:嘈杂环境下的跨语言识别
我选取三星CES2026演讲录音进行测试。该音频存在三重干扰:背景噪音嘈杂、演讲者使用英语但带有韩语口音、录制音量偏低。测试结果显示,Fun-ASR1.5不仅完整转写内容,还根据语气进行了大写强调处理,智能化程度超出预期。
在Code-Switching(跨语言切换)测试中,英日混合音频被准确识别并完整转写,无需任何语种预设。这证明模型的语境理解能力已突破单一语种限制。
应用场景与落地建议
Fun-ASR1.5的三项核心能力对应不同应用场景:多语言识别适用于国际会议和跨境商务沟通;方言识别适用于区域政务服务和民俗文化记录;古诗词识别准确率达97%,可支撑国学教育和有声内容生产。
目前用户可通过魔搭社区直接体验,开发者可通过阿里云百炼平台调用API接口。这套组合覆盖了从个人用户到企业开发者的全层级需求。